* Data integration
: Combines data from multiple sources into a coherent dataset
- Entity indentification problem
: 실제로는 동일한 데이터이나 각각의 소스로부터 다른 방식으로 표현되어 있는 것을 어떻게 합칠 것인가?
- 여러 데이터 베이스에서 수집한 자료를 합칠 때 Redundant data 의 문제는 일어나기 마련이다.
: Redundant attributes may be able to be detected by correlation analysis and covariance analysis
- Correlation Analysis (Nominal Data)
1) 카이스퀘어 검정, chi-square test : o (i,j) is the observed frequency : 관찰값
e (i,j) is expected frequency : 예측값, e (i,j) = #(A = ai) * #(B=bi) / n , (행의합x열의합)/전체수
n is the total # data tuples


- The chi-quare statistic tests the hypothesis that A and B are independent, that, is there is no correlation between them
2) Correlation coefficient (Pearson's product moment), 피어슨 상관계수
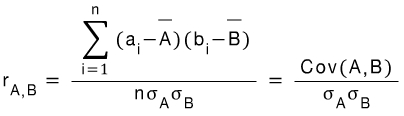
-1 <= r (A,B) <= 1
r (A,B) > 0 , A and B are positively correlated
r (A,B) = 0 , no correlation
r (A,B) < 0 , negatively correlate.

3) Covariance, 공분산
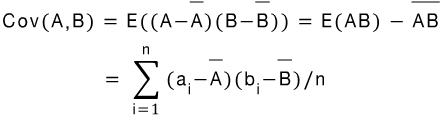
- Positive covariacne : if Cov(A,B) > 0, then A and B both tend to be larger than their expected value.
A와 B 모두 기대값보다 관찰값이 큰 경향이 있다.
- Negative covariance : if Cov(A,B) < 0, then if A is larger than its expected value B is likely to be smaller than its expected value.
만약 A가 기대값 보다 크다면 B의 값은 기대값 보다 작을 가능성이 크다.
- Independence : Cov(A,B) = 0 but the converse is not true
서로 독립이라면 공분산은 0 이다 하지만 공분산이 0이라고 해서 서로 독립관계라고는 말할 수 없다.
'산업공학 > Data Analytics' 카테고리의 다른 글
| ECLAT (0) | 2024.03.25 |
|---|---|
| Data transformation (1) | 2024.03.05 |
| Data preprocessing (0) | 2024.03.05 |
| FP Growth (1) | 2024.03.05 |
| Apriori algorithm (0) | 2024.03.05 |



