Data preprocessing
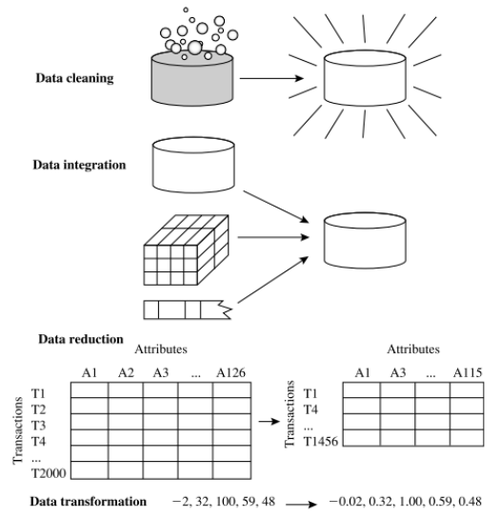
1) data cleaning : 누락 데이터 채우기, 노이즈 제거 , 아웃라이어 제거, inconsistency 수정
- Noisy Data : random error or variance in a measured variable => "SMOOTH" by Binning
First, sort data and partition into (equal-frequency) bins then can smooth by bin means, bin median or bin boundaries
: also can smooth by Regression, Clustering, Combined computer and human inspection
ex) 다음 데이터(4,8,15,21,21,24,25,28,34)를 빈의 평균값을 이용하여 smooth 한다면 :
=> 9개의 데이터 포인트가 있으니 3개씩 3개의 bin으로 나누어 준다.
bin1: 4,8,15 * smooth by bin mean: bin1: 9,9,9
bin2: 21,21,24 bin2: 22,22,22
bin3: 25,28,34 bin3: 29,29,29
2) data integration : integration of multiple database
- Redundant attributes may be able to be detected by correlation analysis and covariance analysis
상관 분석을 통해서 데이터를 합친다.
3) data reduction : obtain a reduced representation of the data set that is much smaller in volume but yet produces the same (almost the same) analytical results
(1) dimensionality reduction: Wavelet transforms, Principal Components Analysis (PCA)
(2) numerosity reduction: Regression and Log-Linear Models, Histograms, clustering, sampling
4) data transformation and data discretization: smoothing, attribute/feature construction normalization, discretization
'산업공학 > Data Analytics' 카테고리의 다른 글
| Data transformation (1) | 2024.03.05 |
|---|---|
| Data integration (1) | 2024.03.05 |
| FP Growth (1) | 2024.03.05 |
| Apriori algorithm (0) | 2024.03.05 |
| Closed Patterns and Max-Patterns (0) | 2024.03.05 |



